PROTEGE LOS CONTENIDOS DE TU BLOG Y EVITA QUE LOS COPIEN
¿Cómo pararles los pies a los scrapers que copian los contenidos de nuestra web?
Poner en marcha un medio online o un blog personal no es una tarea simple: requiere de dedicación, constancia y esfuerzo para ofrecer los mejores contenidos a nuestros lectores. Uno de los objetivos es que nuestros contenidos estén bien situados dentro de los resultados de búsqueda de Google; sin embargo, a veces nos encontramos con una desagradable sorpresa: alguien ha copiado nuestros contenidos y, además, está mejor situado que nosotros en el buscador de Google.

Publicidad
En un medio online o en un blog, el contenido es, sin duda, uno de los aspectos más importantes. Dedicamos recursos y esfuerzos a ofrecer a nuestros visitantes los mejores contenidos y, evidentemente, aspiramos a que nuestros lectores vuelvan y nos tengan dentro de sus páginas de referencia.
Otro de los puntos importantes de cualquier proyecto web es el gran Google: aspiramos a que nuestros contenidos sean indexados por su buscador y, si es posible, que estén bien posicionados (dentro de los primeros resultados) para que los usuarios nos encuentren fácilmente.
El problema lo encontramos cuando detectamos al hacer una búsqueda que alguien ha copiado los contenidos de nuestra página web punto por punto los asume como si fuesen suyos y, encima, termina apareciendo mejor posicionado que nosotros dentro de los resultados de búsqueda de Google.
Esta situación tan frustrante, desgraciadamente, es bastante habitual en el mundo de los medios digitales y existen páginas web que se dedican a copiar descaradamente y mediante procedimientos automáticos el contenido de terceros. Son los 'scrapers', una mala práctica que puede empañar nuestros esfuerzos en posicionamiento en Google por mucho que el buscador penalice el contenido duplicado.
¿Y por qué un scraper copia los contenidos de una web?
El scraping es una técnica que se basa en la copia automática de contenidos, por ejemplo, aprovechando su feed RSS e, incluso, pasando el contenido por Google Translate para realizar traducciones automáticas (no es raro encontrar casos de traducciones del castellano al inglés para así simular que el contenido en inglés es el original y que el contenido en castellano, que realmente era el original, es una copia).
Tomar un buen contenido y replicarlo puede hacer que una web gane en relevancia y, de esta forma, capte más visitas para aumentar sus ingresos por publicidad (y si encima Google posiciona mejor este tipo de páginas, la situación aún es más favorable para el que copia).
Aunque protejamos nuestros contenidos bajo una licencia (ya sea un copyright o bien con una licencia Creative Commons donde tienen que citar la fuente de la que toman el contenido), los scrapers siguen haciendo de las suyas y perjudican la reputación de nuestra web y su posicionamiento.
Además, hay otros efectos secundarios que también afectan al rendimiento de nuestra web puesto que en muchas ocasiones estas copias se hacen tan literales que se copian hasta las rutas de las imágenes (hotlinking) y nosotros acabamos sirviendo (desde nuestros servidores) las imágenes para nuestra página y también para las de los scrapers, soportando así tráfico extra.
Afortunadamente, hay maneras de luchar contra el contenido duplicado y poner en valor nuestro trabajo frente a los que se quieren aprovechar del mismo.
Denunciar ante Google
La primera arma que tenemos a nuestro alcance es la denuncia ante Google. Pues sí, Google nos ofrece la posibilidad de denunciar a los scrapers y, aunque nos parezca llamativo, tiene bastante sentido. A Google le interesa ofrecer la mejor experiencia de uso para su buscador; por tanto, ofrecerles páginas que copian contenidos (y ofrecen publicidad) no es lo que buscan sus usuarios.
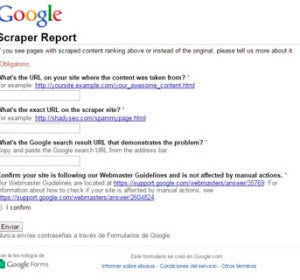
Bajo esta premisa, Google nos ofrece un formulario de denuncia (llamado Scraper Report) en el que tendremos que indicar la URL de nuestro contenido original, la URL del contenido duplicado y la URL de la página de resultados de Google en la que hemos dado con el contenido duplicado (de esta forma Google sabrá qué búsqueda hemos realizado y, si considera válida la denuncia, realizar los ajustes necesarios en el buscador para depurar sus resultados y conseguir ser algo más preciso).
Además de poder denunciar a los scrapers, Google nos ofrece otras herramientas que le ayudan a 'depurar' sus resultados de búsqueda y, en el caso que demos con una página que podamos considerar spam, también existe un formulario específico de denuncia.
Evidenciar que lo que los usuarios están viendo es una copia
Si vemos que la primera de las opciones no funciona, existen instrumentos que podemos utilizar para proteger nuestros contenidos y, en el caso que los copien, quede bastante claro que lo que los usuarios están viendo es una copia.
¿Y qué podemos hacer? Teniendo en cuenta que los scrapers hacen copias literales con 'hotlinking' a nuestras imágenes, poner una marca de agua a nuestras fotos originales es una buena forma de hacer evidente la procedencia del contenido.
Si nuestra web tiene buenos contenidos es lógico que realicemos enlaces a otros artículos que ya hemos publicado. Si dentro de nuestros artículos realizamos varios enlaces a contenidos de nuestro propio sitio web, en el contenido que publique el scraper llevará esos enlaces a nuestro sitio web (evidenciando así de dónde procede el contenido).
Existen plugins de WordPress (como WordPress SEO by Yoast) que introducen una 'firma' en los contenidos cuando estos se publican en el feed RSS. De esta forma, si un scraper copia nuestro contenido a través del RSS, el contenido llevará una firma que, seguramente, habrás visto en más de una publicación: “El contenido XXXX fue publicado primero en YYYY” (y como el scraping es un proceso automático, esa frase también aparecerá en el contenido).

Tomar medidas algo más agresivas
Si las opciones anteriores no te convencen y prefieres optar por medidas algo más drásticas, hay opciones que hacen mucho más complicado que copien nuestros contenidos.
Una de las formas más simples es evitar que nuestros contenidos se puedan copiar bloqueando la típica opción del 'copy-paste'. Aunque nos pueda parecer raro e imposible, se puede evitar que se pueda seleccionar el texto de una web para copiarlo. En el caso que usemos WordPress como sistema es algo tan simple como instalar un plugin como WordPress prevent copy-paste o WP Content Copy Protection y los contenidos quedarán protegidos.
También podemos modificar el archivo .htaccess de nuestra web (si está sobre un servidor web Apache) y bloquear el hotlinking, es decir, hacer que no puedan copiar nuestras fotos. También, gracias a las modificaciones en este archivo, podremos bloquear determinadas IP para que no puedan acceder a nuestra página web.
En el caso que no se nos dé demasiado bien trastear con código y modificar el .htaccess nos parezca complejo, existen algunas páginas web que, directamente, nos proporcionan generadores de código para que modifiquemos nuestro archivo sin necesidad de saber programar.
Publicidad